Crypto Data Backend — FastAPI · Redis · PostgreSQL
I built a backend service to fetch, normalize, and serve cryptocurrency market and on-chain data.
The system had to integrate with multiple external providers, cache responses for speed, persist normalized history in Postgres, and enforce security and fairness through authentication and rate limiting.
This write-up covers the architecture, technical details, and the key lessons learned while building it.
🔹 The Challenge
The backend needed to:
- Fetch & Normalize → Pull data daily from multiple providers (prices, market charts, on-chain metrics) and reshape it into a consistent schema.
- Serve Endpoints → Expose both simple price lookups and time-series queries through clean FastAPI endpoints.
- Cache Aggressively → Store results in Redis with tuned TTLs to ensure sub-200ms responses.
- Persist History → Save normalized data in Postgres across multiple schemas for efficient analytics and queries.
- Secure Access → Protect routes with API keys and JWT-based auth (with admin keys for privileged actions).
- Rate Limit Fairly → Use a Redis-based limiter to prevent abuse and stay within upstream API quotas.
- Support Operations → Provide admins with structured, exportable logs for debugging and audits.
🔹 Architecture
The design ended up as a layered flow:
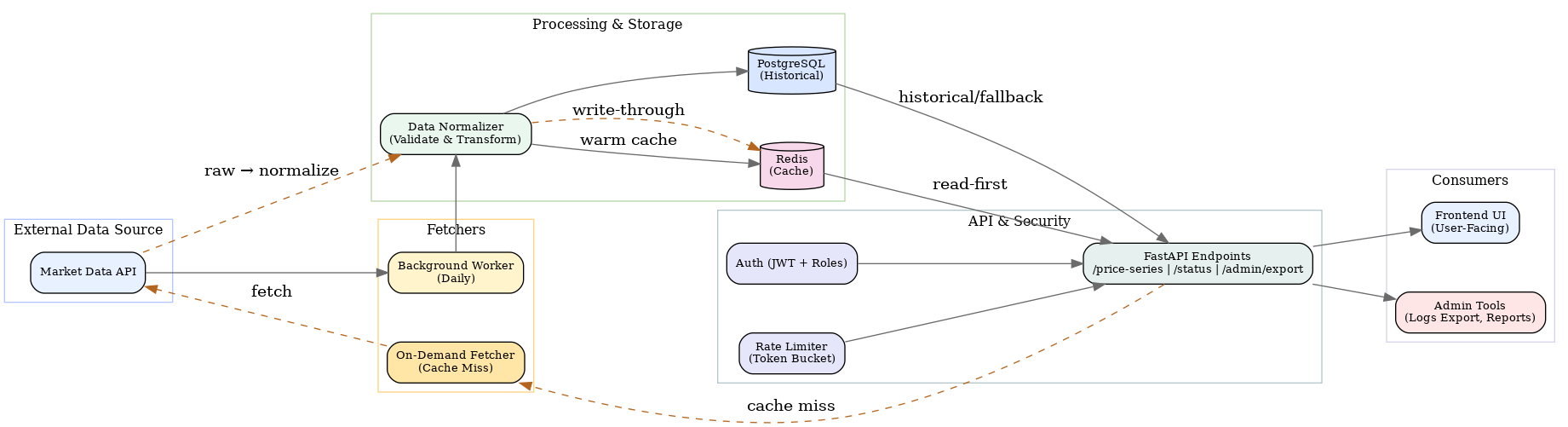
-
External Data Sources
The system had to integrate with multiple upstream sources like CoinGecko and CryptoQuant. Each provider not only had different data formats but also exposed different kinds of information — for example, CoinGecko focused on price/market data while CryptoQuant provided on-chain metrics. To unify them, I added a normalization layer that standardized both the schema and the semantics of the data before persisting it. - Fetchers
I had two paths for bringing in data:- Some background workers that ran daily, pulled data in bulk, normalized it, and saved into both Postgres and Redis with different TTLs.
- Some on-demand fetchers that only ran when Redis or Postgres didn’t have the data. They fetched fresh data, normalized it, and immediately updated Redis/Postgres before returning the result.
-
Normalizer
This was the translator of the system. Since every API returned data in slightly different shapes, I used Pydantic models to validate and reshape everything into a consistent schema. This prevented errors and made downstream querying predictable. -
PostgreSQL
Postgres was the long-term store for all normalized data — not just one table, but multiple schemas for different use cases. For example, I stored simple price lookups in a compact schema keyed by asset/currency, while market chart data (time series) went into a separate schema with asset, interval, and timestamp granularity. This separation kept queries efficient and made analytics more straightforward. -
Redis
Redis was the short-term memory layer, tuned differently for each type of data. Simple price data had a shorter TTL so users always saw near-real-time values, while market chart data (daily/hourly series) had a longer TTL because it changed less frequently. I still treated Redis as a read-through cache — if a key was missing, the fetcher grabbed fresh data, normalized it, updated Redis with the correct TTL, and returned the result immediately. - FastAPI Endpoints
The service exposed three main endpoints:/simple_price→ fetch latest price(s)./market_chart→ fetch historical time-series data./logs/export→ admin-only endpoint to download structured logs.
FastAPI’s input validation caught invalid parameters (like wrongdaysvalues) before they hit the backend logic.
- Authentication & Access Control
Security was handled with API keys and JWT:- Private API key for normal requests.
- Admin key for privileged routes (like log export).
- I also added JWT auth at the FastAPI layer for role-based access control (future-ready).
The client didn’t want to share his private key with me during testing, so I built and tested the entire flow using public keys and Postman. This allowed me to validate auth, caching, and endpoint behavior without exposing secrets.
-
Rate Limiting
I used a fixed-window limiter in Redis: for each API key, keep a counter keyed likerate:<api_key>:<endpoint>:<unix_window>. On each request,INCRthe counter; if it’s the first hit in the window, setEXPIREto the window size. If the count exceeded the configured max requests per window for that key/endpoint, return 429 Too Many Requests until the window rolled over. Limits (window size, max requests) were configurable per provider and per key tier. - Configuration & Environments
All sensitive or changeable values were pulled from environment variables, so I could run the system safely in different contexts.- In dev, I used public API keys, shorter TTLs, and relaxed rate limits. This let me test flows quickly on my own machine without touching production secrets.
- In prod, the client supplied real keys via environment/secret manager, with stricter TTLs and provider-specific rate limits.
This separation made it easy to mimic production behavior locally. For example, I could spin up Postman with my public dev keys, send calls through the endpoints, and watch how caching and rate limits behaved — knowing that the same logic would run in production with just different values.
-
Documentation & Developer Experience
I leaned on FastAPI’s auto-generated Swagger UI at/docsfor interactive exploration of the API.
In addition, I created a separate full technical document (outside the codebase) that explained the architecture, parameter rules, error codes, and expected flows. This was meant for client support and made onboarding much easier. - Consumers
The final users of this system were:- A frontend UI, which called the
/simple_priceand/market_chartendpoints to display charts. - Admin tools, which consumed
/logs/exportfor debugging and auditing.
- A frontend UI, which called the
🔹 Technical Details
-
Background Scheduling
Background workers ran daily on a cron schedule. They refreshed both simple price and market chart datasets, normalizing them and updating Redis + Postgres. This ensured data stayed fresh without hitting external APIs on every request. - Validation Rules
Every request went through strict FastAPI/Pydantic validation:days: positive integer or"max"interval: onlydailyorhourlycurrency: checked against a whitelist of supported symbols
Invalid requests were rejected upfront with 400 Bad Request, preventing wasted API calls and cache pollution.
- Redis Keys & Policy
Keys were structured by dataset:- Simple price →
price:<asset>:<currency>:latest - Market chart →
chart:<asset>:<currency>:<interval>:<days>
Each key carried its own TTL: short for simple price (to feel real-time) and longer for chart data (since daily/hourly series don’t change as often). On cache miss, the system fetched fresh data, normalized it, updated Redis, and returned the result immediately.
- Simple price →
- Error Handling & Retries
- Transient upstream failures → retried with exponential backoff (short delay → longer delay → capped at a max).
- Persistent failures → after retries were exhausted, returned a clear 5xx error instead of partial/stale data.
- Invalid params → 400 (with field-level validation messages).
- Auth failure → 401 (missing/invalid API key or JWT).
- Forbidden → 403 (using a normal key on an admin-only route).
- Rate limit exceeded → 429.
- Unhandled errors → 500.
These clear codes made failure modes predictable and easy to debug.
- Rate Limiting
A fixed-window counter in Redis tracked usage:rate:<api_key>:<endpoint>:<window>. Each request incremented the counter; if it exceeded the configured max per window, the system returned 429 Too Many Requests until the window reset. Limits were configurable per provider and key tier.
- Configuration & Environments
All sensitive and changeable values came from environment variables:- Dev → public keys, shorter TTLs, relaxed limits for rapid iteration.
- Prod → real keys injected via secret manager, stricter TTLs, and provider-specific quotas.
This allowed me to safely simulate production behavior locally with Postman.
- Log Export
All worker actions and API requests were logged in structured JSON with timestamps and context. Admins could download compressed/rotated logs via/logs/export, making audits and debugging easier.
- Documentation & Developer Experience
- FastAPI auto-generated Swagger UI at
/docsand ReDoc at/redoc. - A separate technical document detailed architecture, parameter rules, and error codes.
- A Postman collection with public dev keys was provided for quick testing.
- FastAPI auto-generated Swagger UI at
- Testing & Tooling
- Unit tests with pytest validated schema rules, normalization logic, and error handling.
- Integration tests spun up Redis + Postgres using Docker Compose for end-to-end runs.
- Dockerfile + docker-compose.yml ensured reproducible local builds.
🔹 Learnings
- Normalization was non-negotiable. Multiple upstreams (market vs on-chain) would have been chaotic without one schema.
- Redis caching defined performance. Tuning TTLs separately for simple vs chart data balanced freshness with stability.
- Config-driven design paid off. Env vars let me test with public keys safely while production ran securely with stricter limits.
- Hybrid auth worked well. Keys kept things simple; JWT made the service ready for future RBAC.
- Docs mattered. Swagger for devs, plus an external doc and Postman env for client ops.
- Admin log export proved invaluable. It gave visibility into background jobs and requests.
- Strict validation prevented waste. Bad requests were cut off early with clear 400s.
🔹 Reflection
What began as a simple “fetch and serve crypto data” grew into a robust microservice. By layering fetchers, normalization, caching, validation, authentication, rate limiting, environment-driven configs, and comprehensive documentation, the system became reliable, predictable, and extensible.
The lessons I’ll carry forward: normalize early, cache aggressively, validate strictly, make configs flexible, document from the code, and always give admins visibility.